Assigned:
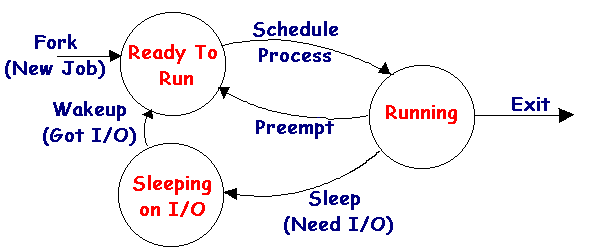
It is important to note that process scheduling gets done between chunks of "real work". The CPU happily chugs away running a single process for a specific amount of time. This is "real work". The system keeps time with a hardware clock that interupts the CPU at a fixed, hardware-dependent rate, typically between 50 and 100 times a second. Each occurence of a clock interupt is called a clock tick. The system allows a process to execute on the CPU for a specific number of clock ticks before it gets moved to another state. This number is called the system's timeslice. After each clock tick, the CPU begins to execute operating system code, part of which is job scheduling. In the diagram above each circle contains none, one, or more processes and the processes are transitioned between circles during the operating system code that does job scheduling. The transistions are explained as follows:
The system will have the following behavior. You must have a way to keep time intervals (clock ticks) during the execution of the system. A simple approach to this problem might be to use a loop and for each iteration, increment the clock. Seven things should be done in the scheduling loop during each cycle, the first six of which pretty much map directly to the transitions of the diagram above. Your main loop will something like the following:
1. if there are new jobs, then put them in ready
to run state
2. if the job currently running has used up its
timeslice, then put it back in the ready to run state
3. if the job currently running has requested I/O,
then move it to slepping on I/O state
4. if a job was just swapped out, then choose a
new job to swap in
5. for all jobs waiting for I/O, check if the request
has been satisfied
6. if a job's I/O has completed move it to ready
to run state
7. keep track of statistics
For this simulation jobs will do no "real" work; i.e. your simulation will implement what happens when the CPU invokes the operating system process scheduler. You can think of this project as a function call inside the operating system. A function call that updates all job states and sets up the next job to run, so that when the function call completes, the CPU has next job and can begin to run it.
Since our simualted jobs are doing no "real work", we have a little problem. If they are not actually executing code, they cannot request I/O. If they cannot request I/O, we can't transition from running to sleeping on I/O. And since there is no real I/O going on, I/O can never complete, so we cannot transition from sleeping on I/O to a ready to run. This is a problem. But we have a solution. When a job is in the running state you will have a function that randomly decides whether or not the job has requested I/O. When a job is in the "waiting for I/O" state, you will have a function that randomly decides whether or not I/O has completed for that job. These functions are given below.
#define CHANCE_OF_IO_REQUEST 10
#define CHANCE_OF_IO_COMPLETE 4
int IO_request() {
if( rand() % CHANCE_OF_IO_REQUEST == 0) return
1;
else return 0;
}
int IO_complete() {
if( rand() % CHANCE_OF_IO_COMPLETE == 0) return
1;
else return 0;
}
(Note: In order to use the rand() function, your simulator needs to seed the random number generator).
Jobs in this simulation will be simulated using a job data file that contains 4 columns. The format is :
Process Id : Arrival time : Service time : PriorityFor example the data file
123:0:10:1
124:1:20:0
describes a simulation that has two jobs. The first has a pid of 123, an arrival time of zero (when the simulation starts), needs to do 10 clock ticks of work, and has a priority of 1. The second job has a pid of 124, arrives at clock tick 1, needs to do 20 clock ticks of work, and has a priority of 0.
The behavior of all the jobs your simulator will handle is described
in the data file attached. Associated with every job is a unique process
id (pid), the arrival time for the given job, a service time (how
long a job has until completion, i.e. how long the jobs "real work" will
take), and a priority rating (for this simulation there will be five priorities,
numbered 0-4 with 0 being the highest priority). Please do not change this
data file, your grade will be based on a specific output generated by the
given job attributes.
Your project's main function could look something like this:
clock=0;
seed the random number generator
add new incoming jobs to the ready to run state
clock++;
while(there are jobs in the system) {
current_job = choose job to execute
while( 1 ) { /* this loop is the main
process management loop */
add new incoming jobs to the
ready to run state
while there are
jobs waiting for I/O
status = IO_complete() /* check if this job's I/O
is complete */
if status == 1
then put the job whose I/O has completed on the ready to run queue
if this job has finished its work (if time remaining is 1)
then mark current_job as swapped out (job complete, exit)
if there are now higher priority jobs on the ready to run state
then mark current_job as swapped out (preempted)
/* check for I/O request from current_job */
if the job is not complete
then status = IO_request()
if status == 1
/* need to do I/O */
then mark current_job as swapped out (sleeping on I/O)
else if this job has been on the CPU for an entire timeslice
then mark the job as swapped out (end of timeslice) and move it to
the ready to run state
do bookkeeping and statistics
clock ++
if current_ job was swapped out
then move the job to the appropriate queue and break from this loop
}
}
Note: The choose job to execute line will be your 2 different scheduling functions. (If the inner loop above is well thought out, it should not have to change when your scheduling algorithm changes.) Also, make sure you account for the case that no processes will run. In this case, run an idle process (no statistics need to be generated for this pseudo process).
The simulation needs to be deterministic so the TA can grade it without having to check everyone's output by hand. In order for this to happen, the calls to rand() inside IO_request and IO_complete need to be called in the same order in everyone's implementation. The order of calls are given in the above pseudo code for your main. I.e., for each iteration of the inner loop you must first call the IO_complete, in a FIFO fashion, for all currently waiting jobs in the I/O queue, then call IO_request for the current job. Your implementation must follow this order. Also everyone's implementation needs to call srand() before the main loop is started. To be deterministic everyone will use "1" as the seed to srand().
The output should be standard and follow the format given below:
| Total time | Total time | Total time Job# | in ready to run | in sleeping on | in system | state | I/O state | =========+=================+=================+=============== pid0 | XXX | XXX | XXX pid1 | XXX | XXX | XXX pid2 | XXX | XXX | XXX pid3 | XXX | XXX | XXX ... ... ... pidN | XXX | XXX | XXX ============================================================= Total simulation run time: XXX Total number of jobs: XXX Shortest job completion time: XXX Longest job completion time: XXX Average job completion time: XXXYour program in required to produce verbose output if given the "-v" flag on the command line. The verbose output will be written to stderr every clock tick and consist of the following one line format.
# while the systems has jobs
<clock tick>: scheduled: <pid>, <remaining time
for this job>
io_request:
<"true"|"false">
<io requests
completed> # a list of pids or "none"
if no I/O
# completed
<job state at end of loop>
# one of "preempted", "still running", or "sleeping"
For example, the job file above would produce the following verbose output to stderr:
0:123:9:false:none:preempted
1:124:19:false:none:still running
2:124:18:false:none:still running
3:124:17:false:none:still running
4:124:16:true:none:sleeping
5:123:8:false:none:still running
6:123:7:false:0:preempted
7:124:15:true:none:sleeping
...
...
For example, assume the following things happen during clock tick 45:
job 123 is running, it does not request I/O, it has 15 clock ticks until
it exits, it has not used its entire timeslice, and the I/O completes for jobs 234,345 and 456. The verbose output for that cycle would be:
45:123:15:false:234,345,456:still running
If no I/O had completed it would be:
45:123:15:false:none:still running
Your simulator must read the input file from stdin and write
its output to stdout. So the program will be run as follows:
% my_simulator < input_file.txt > output_file.txt
It will be faster and easier to test your simulator, if all the inputs
can be changed from the command line. i.e.
> simulator -v -ts 3 -s 1 -r 10 -c 4 < input_file.txt > output_file.txt
Where ts is the time slice, s is seed value, r
is I/O request chance, c is I/O complete chance, and verbose output
is on. But by no means is this required.
If you are interested in the browsing the source code for the Linux process scheduler, it can be found here in /kernel/sched.c.
Good luck!!
% submit cs421_02 proj1 my_cool_simulator.c my_cool_simulator.h