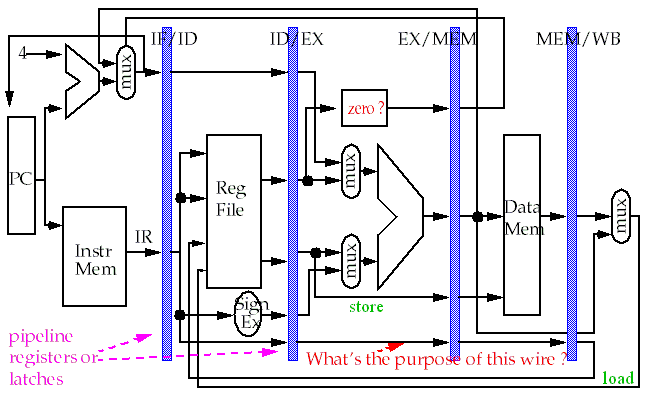
-
Can data path resources, such as the adder, be shared ?
-
Pipeline Issues
:
-
Separate instruction caches and data caches eliminates conflicts for memory access in IF and MEM.
-
Note that the memory system must deliver
5x
the bandwidth over the unpipelined version.
-
The register file is used in two stages, reading in ID and writing in WB.
-
Two reads and one write required per clock.
-
More importantly, what happens when a read and a write occur to the same register ?
-
What about branch instructions and the PC ?
-
Branches change the value of the PC -- but the condition is
not
evaluated until MEM !
-
If the branch is taken, the instructions fetched
behind
the branch are invalid !
-
This is clearly a serious problem that needs to be addressed.
-
Pipelining
decreases
execution time but can
increase
cycle time.
-
Throughput
is
increased
since a single instruction (ideally) finishes every clock.
-
However, it usually
increases
the
latency
of each instruction.
-
Why ?
-
Imbalance among the pipe stages:
-
The slowest stage determines the clock cycle time.
-
Pipeline overhead:
-
Pipeline register delay
. Adding registers, adds logic between each of the stages (plus constraints on setup and hold times for proper operation -- but we won't talk about those.)
-
Clock skew
. The clock must be routed to possibly widely separated registers/latches, introducing delay in signal arrival times.
-
In the limit, clock cycle time is bound by the sum of the clock skew and latch overhead.
-
Instruction regularity
:
-
With a pipeline, differences in instruction CPI can
NOT
be taken advantage of.
-
In the unpipelined version, a store instruction finishes after MEM, 4 clocks rather than 5. The same is true of ALU instructions.
-
With pipelining, we can not start the next instruction one clock earlier since it is already in the pipeline.
-
Therefore, CPI may
not
be decreased by the full number of pipeline stages (ideal case is usually not achievable).
-
This effect reduces the maximum pipeline
depth
.
-
Pipelining can be thought of as reducing the CPI.
-
This
increases
throughput even though clk cycle time is
increased
.
-
A hazard is a condition that prevents an instruction in the pipe from executing its next scheduled pipe stage.
-
There are three types of hazards.
-
Structural hazards
-
These are conflicts over hardware resources.
-
Data hazards
-
These occurs when an instruction needs data that is not yet available because a previous instruction has not computed (FP pipes) or stored it.
-
Control hazards
-
These occur for branch instructions since the branch condition (for compare and branch) and the branch PC are not available in time to fetch an instruction on the next clock.
-
Hazards in the pipeline may make it necessary to
stall
the pipeline.
-
Stall definition:
-
The simplest way to "fix" hazards is to stall the pipeline.
-
This means suspending the pipeline for
some
instructions by one or more clk cycles.
-
The stall delays all instructions issued
after
the instruction that was stalled.
-
A pipeline stall is also called a
pipeline bubble
or simply
bubble
.
-
Stall location:
-
Note that a bubble need
not
be inserted at the start of an instruction.
-
It can be inserted in the middle.
-
A bubble is inserted whenever the pipeline must be suspended for one instruction to allow a
previous
instruction to proceed.
-
The previous instruction MUST proceed in order for the hazard to clear.
-
This is unlike a cache miss, in which all instructions (before and after) are stalled.
-
No new instructions are fetched during a stall.
-
To emphasize, all instructions issued
later
than the stalled instruction are stalled.
-
Effect on pipeline speedup:
-
Pipeline stalls decrease performance from the ideal !
-
Every cycle the pipeline is stalled results in a cycle in which an instruction is NOT issued.
-
And thus is a cycle in which an instruction is NOT completed.
-
Lets start with the basic formula:
-
Remember our performance equation: (IC*CPI*Clk cycle time):
-
Effect on pipeline speedup:
-
Note that pipelining can be thought of as
decreasing CPI
or
decreasing clock cycle time
. Let's focus on the former.
-
Assuming the ideal CPI is 1:
-
Let's ignore increases in clk cycle time (due to pipeline overhead):
-
Let's further assume unpipelined CPI is equal to the depth of the pipeline (ignore shorter instruction CPIs).
-
Effect on pipeline speedup:
-
If we include the effect of pipeline overhead, we get:
-
and the rest can be derived.
-
As long as CPI and clock cycle are calculated properly for both machines, this formula will hold true.