-
Performance of Branch Schemes
:
-
Here we assume that there are
no
other delays from data hazards (an ideal CPI of 1).
-
We can calculate pipeline stalls from branches by:.
-
Example:
-
Suppose we have a CPU that has a single branch delay slot.
-
This slot can be filled with a useful instruction
65%
of the time.
-
In addition, the branch condition is not known for
two
cycles beyond the delay slot.
-
If these are predicted properly, there is no penalty.
-
If they are mispredicted, the two intervening instructions must be cancelled.
-
Forward branches are always
predicted not taken
, while backward branches are always
predicted taken
.
-
Forward branches make up
75%
of all branches, and branches are
20%
of all instructions.
-
If
50%
of forward branches and
85%
of backward branches are taken.
-
What is the new CPI (assuming the original CPI is 1)?
-
Solution:
-
First, let's calculate the number of stall cycles.
-
For 35% of the branch instruction, the delay slot isn't filled.
-
This adds 0.35 cycles of branch stalls.
-
50% of forward branches suffer a 2 cycle penalty.
-
Since 75% of branches are forward, this contributes
 cycles.
cycles.
-
Similarly, 15% of backward branches suffer a 2 cycle penalty, adding
 cycles.
cycles.
-
The total branch penalty is thus 0.35 +
0.75
+ 0.075 = 1.175 cycles.
-
Since branches make up 20% of all instructions, the penalty to the CPI is
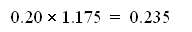 cycles.
cycles.
-
This makes the new CPI 1.235.
-
Compilers and static branch prediction
:
-
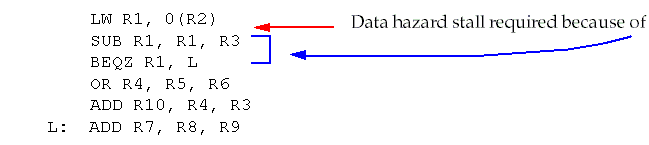
Having accurate information about branch behavior at compile time is also helpful for scheduling
data
hazards:
-
Suppose we knew that the branch was
almost always taken
and value in R7 was not needed in the fall through part:
-
Compiler could move ADD R7, R8, R9 after the load instruction.
-
Suppose we knew that the branch was
rarely taken
and value in R4 was not needed on the taken path:
-
Compiler could move OR R4, R5, R6 after the load instruction.
-
These optimizations are in addition to any branch delay scheduling.
-
Compilers and static branch prediction:
-
In order to reduce branch stall penalties, the compiler can:
-
Reorder instructions
:
-
As we have seen in previous examples.
-
Predict all branches taken
-
This is surprisingly effective since 85% of backward branches and 60% of forward branches are taken.
-
However, this still leaves more than a third of the branches improperly predicted.
-
For some programs, this method is excellent (< 10% mispredictions), but for others, it does badly (> 50%).
-
Compilers and static branch prediction:
-
Predict forward not taken and backward taken
-
This scheme is similar to predicting all branches as taken except that it uses information about the types of branches.
-
Forward branches are likely part of
if-else
constructs, and may be less likely to be taken.
-
Backward branches are usually part of
loops
and thus more likely to be taken.
-
This is particularly true if the compiler
reorganizes
if-else
constructs to make the non-taken fork of the branch more likely.
-
However, this method won't perform much better than simply predicting
not-taken
.
-
Compilers and static branch prediction
:
-
Use profile information from previous runs
-
The compiler can instrument the code using the profile information from previous runs of the program.
-
It can build a higher performance program by predicting that branches taken in the practice run(s) will be taken in the final version.
-
It is not perfect since many branches are both taken and not taken in the course of execution.
-
But it does provide better prediction than other static methods.
-
Misprediction rates for this method range from 5% to 20%.
-
This is true even if
different
input data is used for the program.
-
Compilers and static branch prediction
:
-
Studies have shown that
profile-based prediction
is almost always better than
predict-taken
or other non-profile-based methods.
-
Since
profile-based prediction
is so good, why not use it ?
-
Dynamic branch prediction
provides a better solution (which we'll discuss in a week or two.)
-
Why is pipelining difficult ?
-
Now that we've seen how pipelining can be done and how to detect and resolve hazards, the question arises: what's so hard about this?
-
Exceptions
-
Instruction set complications
-
Exceptions
-
The problem is that an instruction in the pipeline can raise an exception that may force other instructions in the pipeline to be aborted.
-
These other instructions may have
altered
the state of the machine.
-
More importantly, exceptions introduce the possibility that an exception in a later instruction (i.e. in ID or EX) will prevent a previous instruction (i.e. in MEM or WB) from completing.
-
Exception causes
-
I/O device requests
-
User OS service requests
-
Breakpoints
-
Integer arithmetic overflow/underflow
-
FP arithmetic anomaly
-
Page fault
-
Misaligned memory accesses
-
Memory protection violations
-
Hardware malfunctions
-
Undefined instructions
-
Exception characteristics
-
Synchronous vs. asynchronous
-
Does the exception come as a result of execution, at the same place for every run of a program with the same data and memory allocation ?
-
Or is it generated external to the CPU ?
-
Asynchronous
events can usually be handled after the completion of the current instruction, making them easier to handle.
-
User requested vs. coerced
-
Did the user request an exception, i.e. through an exception instr. ?
-
Or did it happen as a result of something beyond the user program's control, i.e. a hardware event ?
-
Coerced exceptions are harder to implement since they are not predictable.
-
Exception characteristics
-
User maskable vs. non-maskable
-
Can the user prevent the hardware from responding ?
-
Note that for maskable interrupts, the user can choose to respond to them, and therefore they are similar to non-maskable interrupts.
-
In other words, maskable interrupts must still be handled properly.
-
Within vs. between instructions
-
Does the exception prevent instruction completion, by occurring in the middle of execution ?
-
Or is it recognized between instructions.
-
Exceptions occurring within instructions are usually synchronous, since the instruction triggers the exception.
-
Within
is more difficult to implement than
between
since the former must be restarted.
-
Exception characteristics
-
Resume vs. terminate
-
Does the exception stop the program from running ?
-
Or must the program be restarted after the interrupt ?
-
Restarting is harder (obviously), and is the more common case.
-
The most difficult case is handling interrupts within an instruction, where the instruction must be resumed.
-
In this case, another section of code (usually OS code) must be invoked to:
-
Save the state of the executing program.
-
Fix the cause of the exception.
-
Restore the state of the original program, and restart it as if nothing had happened.
-
Exceptions of this type occur for
virtual memory management
systems.
-
Machines that can perform these operations are called
restartable
.
-
For exceptions that occur
within
instructions (i.e. in EX or MEM) and must be
restarted
(page fault), the pipeline state must be saved.
-
Pipeline control accomplishes this by:
-
Inserting a trap instruction into the pipeline on the next IF.
-
Turn off all writes for the faulting instruction and the instructions following it in the pipeline.
-
Previous instructions are allowed to complete.
-
Save the PC of the faulting instruction so it can be restarted. (Done by the OS exception handling routine.)
-
This method requires as many PCs as there are delay slots, since the instructions currently in the pipeline may not be sequentially related !
-
In any case, we will have to save at least one PC value: the location of the faulting instruction.
-
Precise vs. imprecise exceptions
-
A
precise
exception is one in which:
-
All instructions
before
the faulting instruction complete AND
-
And instructions
following
the faulting instruction, including the faulting instruction, do not change the state of the machine.
-
Under this model, restarting is easy:
-
Simply re-execute the original faulting instruction.
-
Or, if it is not a resumable instruction, i.e. an integer overflow, start with the next instruction.
-
Often, precise exceptions are difficult because of
out-of-order
instruction completions and
out-of-order
exception occurrences.
-
This leads to
imprecise
exceptions.
-
This is true of floating point pipelines more so than integer pipelines.
-
In general, integer exceptions are precise, while FP exceptions may not be.
-
Exception ordering:
-
Suppose two consecutive instructions cause exceptions:
-
In this case, the memory exception comes in the same cycle as the overflow exception.
-
In this case, the first one (the page fault) should be handled and the second instruction canceled.
-
Exception ordering:
-
What if fetching the ADD instruction caused a page fault ?
-
Then, the ADD instruction page fault occurs
before
(in time) the LW page fault.
-
However, we must finish the LW before handling the ADD page fault (if we are implementing precise exceptions.)
-
This is done by keeping an
exception vector
for each instruction:
-
If an exception is posted, it is added to the vector and all writes that affect system state are disabled.
-
Exception ordering:
-
When the instruction is about to exit the pipeline (MEM/WB), any pending exceptions for the instruction are examined.
-
If an instruction generates
multiple
exceptions, the exception occurring in the earliest stage takes precedence.
-
Note that, for the DLX, the faulting instruction has not updated any state (since all updates occur in WB.)
-
Many CPUs support
both
for performance reasons, since precise exception mode is much slower.
-
Instruction set complications
-
An instruction is
committed
when it is guaranteed to complete.
-
On DLX, all instructions are committed at the end of MEM.
-
Since no updates occur before instructions commit,
precise
interrupts are straightforward.
-
In most RISC systems, each instruction writes only one result.
-
This means that the instruction can be cancelled any time before the instruction is committed, with no harm to the system state.
-
This is not true for many CISC machines, i.e. VAX
-
On these machines, the system state may be modified well before the instruction or its predecessors are committed.
-
For example, if an instruction using autoincrement mode is aborted because of an exception, then the machine state may have been altered.
-
This leads to an
imprecise
exception making it difficult to restart the instruction.
-
Instruction set complications
-
The situation is worse for instructions that access and write memory in multiple places.
-
These instructions can generate multiple faults.
-
Therefore, it becomes difficult to know where to resume.
-
For
string
instructions, the CPU must also know how far into the operation it was when the exception occurred.
-
This is usually solved by using general purpose registers as scratch space (that are saved and restored.)
-
The general solution used by more complex instruction set machines is to pipeline the microcode.
-
In fact, RISC has often been compared to having the microcode as the actual assembly language.
-
Instruction set complications
-
Multi-cycle operations:
-
Implementing instructions vary widely in the number of clock cycles they take to complete makes building a pipeline more complex.