-
Handling exceptions.
-
Exceptions are difficult because instructions may now finish
out of order
.
-
Consider the following sequence:
-
In this example,
ADDF
and
SUBF
are expected to complete before
DIVF
.
-
Out-of-order completion.
-
Suppose
SUBF
caused an arithmetic exception at a point where
ADDF
completed but
DIVF
has not.
-
The result is an
imprecise exception
. Fix here is to let pipeline drain.
-
Worse, suppose
DIVF
had an exception after
ADDF
completed.
-
Since
ADDF
destroys one of its operands, we can not restore the state to what it was before the
DIVF
instruction, even with software !
-
Handling exceptions,
first
solution (of four):
-
Ignore the problem (imprecise exceptions):
-
This may be fast and easy, but it's difficult to debug programs without precise exceptions.
-
Many modern CPUs, i.e. DEC Alpha 21064, IBM Power-1 and MIPS R800, provide a
precise
mode that allows only a single outstanding FP instruction at any time.
-
This mode is much slower than the
imprecise
mode, but it makes debugging possible.
-
Handling exceptions,
second
solution:
-
Buffer the results and delay commitment
:
-
In this case, the CPU doesn't actually make any state (register or memory) changes until the instruction is guaranteed to finish.
-
This becomes difficult when the difference in running time among operations is large.
-
Lots of intermediate results have to be buffered (and forwarded, if necessary).
-
Handling exceptions, variations of the
second
solution:
-
History file:
-
This technique saves the original values of the registers that have been changed recently.
-
If an exception occurs, the original values can be retrieved from this
cache
.
-
Note that the file has to have enough entries for
one
register modification per cycle for the longest possible instruction.
-
Similar to the solution used for the VAX for autoincrement and autodecrement addressing.
-
Handling exceptions, variations of the
second
solution:
-
Future file:
-
This method stores the
newer
values for registers.
-
When all
earlier
instructions have completed, the main register file is updated from the future file.
-
On an exception, the main register file has the
precise
values for the interrupted state.
-
Handling exceptions,
third
solution:
-
Keep enough information for the trap handler to create a
precise
sequence for the exception:
-
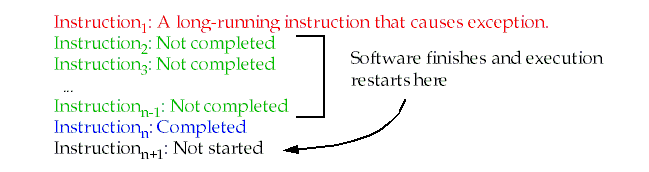
The instructions in the pipeline and the corresponding PCs must be saved.
-
After the exception, the software finishes any instructions that precede the latest instruction completed.
-
Technique is used in the SPARC architecture.
-
Handling exceptions,
fourth
solution:
-
Allow instruction issue only if it is known that all previous instructions
will complete without
causing an exception.
-
The floating point function units must determine if an exception is possible early in the EX stage, first couple clocks,
-
In order to prevent the following instructions from completing.
-
Sometimes it requires stalling the pipeline in order to maintain
precise
interrupts.
-
The R4000 and Pentium solution.
-
Avoid
variable
instruction lengths and running times whenever possible
:
-
Variable length instructions complicate
hazard detection
and
precise exception
handling.
-
Sometimes it is worth it because of performance adv., i.e.,
caches
.
-
Cause instruction running times to vary, when they miss.
-
Many times, the added complexity is delt with by freezing the pipeline.
-
Avoid sophisticated addressing modes
:
-
Addressing modes that update registers (post-autoincrement) complicates exceptions and hazard detection.
-
It also makes it harder to restart instructions.
-
Allowing addressing modes with
multiple
memory accesses also complicates pipelining.
-
Don't allow self-modifying code
:
-
Since it is possible that the instruction being modified is already in the pipeline, the address being written must constantly be checked.
-
If it is found, then the pipeline must be flushed or the instruction updated !
-
Even if it's not in the pipeline, it could be in the instruction cache.
-
Avoid implicitly setting CCs in instructions
:
-
This makes it harder to
avoid control hazards
since it's impossible to determine if CCs are set on purpose or as a side effect.
-
For implementations that set the CC almost
unconditionally
:
-
Makes instruction
reordering
difficult since it is hard to find instructions that can be scheduled between the condition evaluation and the branch.
-
Eight stages:
-
IF
-
First half of instruction fetch. PC selection occurs. Cache access is initiated.
-
IS
-
Second half of instruction fetch.
-
This allows the cache access to take two cycles.
-
RF
-
Decode and register fetch, hazard checking, I-cache hit detection.
-
EX
-
Execution: address calculation, ALU Ops, branch target calculation and condition evaluation.
-
DF/DS/TC
-
Data fetched from cache in the first two cycles.
-
The third cycle involves checking a tag check to determine if the cache access was a hit.
-
WB
-
Write back result for loads and R-R operations.
-
Possible stalls and delays:
-
Load delay:
two cycles
-
The delay might seem to be three cycles, since the tag isn't checked until the end of the TC cycle.
-
However, if TC indicates a miss, the data must be fetched from main memory and the pipeline is backed up to get the real value.
-
Branch delay:
three cycles
(including one branch delay slot)
-
The branch is resolved during EX, giving a 3 cycle delay.
-
-
The first cycle may be a
regular
branch delay slot (instruction always executed) or a
branch-likely
slot (instruction cancelled if branch not taken).
-
-
MIPS uses a
predict-not-taken
method presumably because it requires the least hardware.
-
Effects of longer pipeline:
-
In addition to the longer (and possibly more frequent) stalls just mentioned, the longer pipeline requires additional
forwarding
hardware.
-
It also requires more complex
hazard detection
to find dependencies in the additional stages.
-
Benefits of longer pipeline
-
The major benefit to a longer pipeline is that each stage may be shorter.
-
This means that the clock cycle can be shorter, allowing more instructions to be issued in a fixed time.
-
Of course, the added stalls might eat up this benefit, but the hope is that at least some speedup will be left.
-
Performance issues (integer only)
-
The ideal CPI for the pipelined CPU is 1.
-
The biggest contributor to stalls is branch stalls.
-
Load stalls contribute very little.
-
This is probably because the compiler can usually reorganize code to avoid stalling on loads.
-
Since load latency is two cycles, though, the job is harder than it might be on processors with a single-cycle latency.
-
Pipelining is a good way to improve performance
-
These days, pipelining is one of the best ways to improve performance.
-
It allows the CPU to issue one instruction per cycle even when finishing an instruction takes many cycles.
-
This has been the major factor allowing consumer-level microprocessors to run at 150 MHz or higher.
-
In the next few weeks, we'll cover more ways to squeeze performance out of the CPU.