-
The basics
-
Until now, we have focused on overcoming
data
hazards.
-
However,
control
hazards contribute greatly to reduced CPI, especially as pipelines become longer.
-
This is even more evident for machines that issue multiple instructions per cycle (CPI < 1).
-
Branches arrive n times more frequently in a n-issue machine.
-
The latency of resolving a branch does not decrease, so the CPI is more significantly affected than it is for a single-issue machine.
-
Static vs. dynamic prediction
-
In
static
prediction, all decisions are made at compile time.
-
This does not allow the prediction scheme to adapt to program behavior that changes over time.
-
Effects of prediction on performance:
-
Accuracy
-
Clearly, the accuracy of a branch prediction scheme impacts CPU performance.
-
A scheme that is
not
accurate may make CPU performance worse than it would be without prediction.
-
Latency
-
There are two orthogonal aspects for each branch.
-
A branch may be
taken
or
not taken
.
-
A branch may be
correctly
or
incorrectly predicted
.
-
This means there may be as many as four different latencies for a single branch instruction.
-
Branch-Prediction Buffer
(branch history table):
-
The simplest thing to do with a branch is to
predict
whether or not it is taken.
-
This helps in pipelines where the
branch delay
is
longer
than the time it takes to compute the possible
target PCs
.
-
If we can save the decision time, we can branch sooner.
-
Note that this scheme does NOT help with the DLX.
-
Since the branch decision and target PC are computed in ID, assuming there is no hazard on the register tested.
-
General idea:
-
Keep a buffer (cache) indexed by the lower portion of the address of the branch instruction.
-
Along with some bit(s) to indicate whether or not the branch was recently taken or not.
-
If the prediction is
incorrect
, the prediction bit is inverted and stored back.
-
The branch direction could be
incorrect
because:
-
Of misprediction OR
-
Instruction mismatch
-
In either case, the worst that happens is that you have to pay the full latency for the branch.
-
Problem:
-
In cases in which the branch is
almost always taken
, this scheme will likely predict
incorrectly twice
.
-
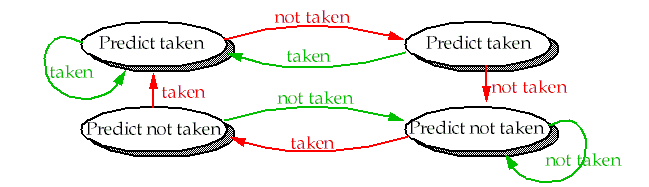
2-bit scheme fixes this problem:
-
For the 2-bit predictor scheme:
-
This allows the accuracy of the predictor to approach the taken branch frequency (i.e. 90% for highly regular branches.)
-
n-bit prediction
:
-
Keep an n-bit saturating counter for each branch.
-
Increment it on branch
taken
and decrement it on branch
not taken
.
-
If the counter is greater than or equal to half its maximum value, predict the branch as taken.
-
This can be done for any n,
-
But it turns out that
n=2
performs almost as good as other values for n.
-
Location of the prediction bits:
-
"Special cache"
-
This cache would be accessed during IF (with the PC), and the prediction bits used during ID (if the instruction is decoded as a branch).
-
Instruction cache
-
Requires more space (since the instruction cache is usually much larger than the "special cache".)
-
However, this reduces the likelihood that "conflicts" occurs between different branches.
-
Accuracy of branch prediction:
-
Misprediction rates range from
1%
to
18%
.
-
A 4K special cache was used to collect this data.
-
Remember that static rates were around
30%
for many programs.
-
Exploiting more ILP is critical to the accuracy of our predictor.
-
How can we improve the accuracy ?
-
Increasing the size of the cache does not help (much).
-
Increasing the number of bits beyond 2 does not help (much).
-
What if we consider the behavior of "surrounding" branches ?
-
This works particularly well if there are common "paths" through code that require several branches, i.e.,
-
B3 is
correlated
with B1 and B2.
-
If both `if stmts' are true, then aa != bb is FALSE.
-
Note that if b1 is
not taken
then b2 will
not be taken
.
-
A
correlating predictor
can take advantage of this.
-
Two-level predictors:
-
Keep track of the behavior of
previous
branches, and use that to predict the behavior of the
current
branch.
-
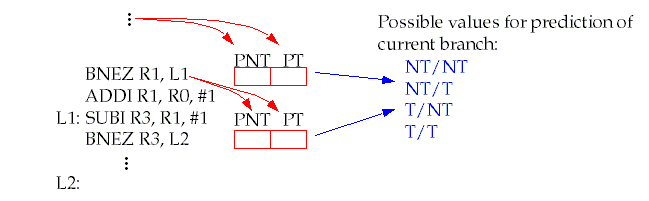
To implement this, each branch instruction has two bits assigned:
-
One bit that predicts the direction of the current branch if the previous branch was
not taken
(PNT).
-
One bit that predicts the direction of the current branch if the previous branch was
taken
(PT).
-
There are four possibilities:
-
Two-level predictors: How does this improve on the accuracy ?
-
Assume the value of d alternates between 2 and 0 in a loop.
-
Observations for the (1,1) predictor scheme:
-
The correct prediction of b2 shows the advantage of correlating predictors.
-
The correct prediction of b1 is due to the choice of d, since there is no obvious correlation in this case.
-
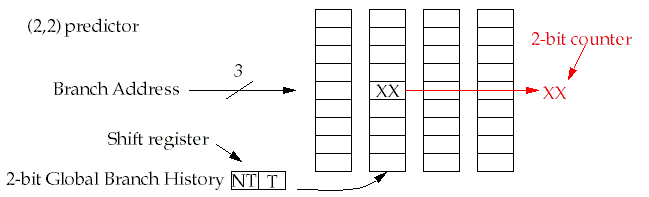
(m,n) predictors
-
Use the behavior of the last
m
branches to choose from one of 2
m
branch predictors, each of which is an
n-bit
predictor.
-
(m,n) predictors
-
This gives better prediction rates than conventional n-bit prediction because it allows several "contexts."
-
The Global Branch History can be implemented using a
shift register
that shifts in the branch behavior (NT or T) when the branch is executed.
-
Note that since the branch prediction buffer is NOT a cache, there's no guarantee that the predictions correspond to the "correct" branch instruction.
-
Branch-Target Buffers
(BTB) (or Branch-Target Caches):
-
So far, we've focused only on predicting whether a branch is taken or not.
-
However, we need to know which address to fetch from ASAP if we want to reduce stalls even further, ideally to 0.
-
We must do this even
before
the CPU knows the instruction is a branch.
-
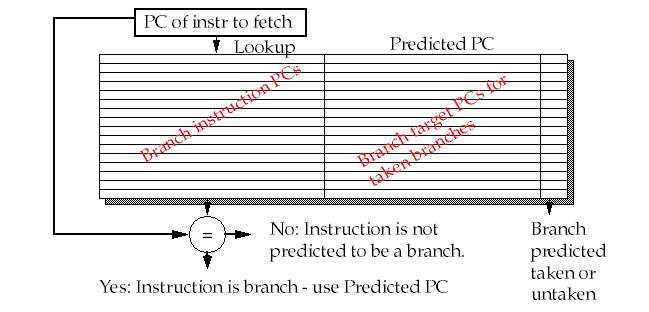
Branch-Target Buffer structure:
-
A branch target buffer is very similar to a cache.
-
It's indexed exactly like a cache, except that the "value" in the cache is the address of the next instruction not the contents of the memory location.
-
Branch target buffer structure:
-
Basic operation:
-
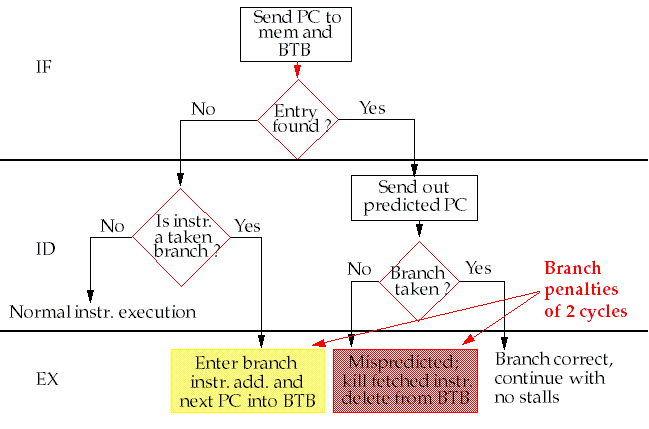
If a hit occurs in the BTB, the CPU fetches the next instruction from the address stored in the BTB, and not PC + 4.
-
This occurs by the end of IF !
-
Basic operation:
-
Note that we must compare the
entire address
(unlike prediction buffers.)
-
If an incorrect match occurs (current instruction is NOT a branch instruction), then we will slow things down, since the Predicted PC is always non-sequential by definition (and therefore, incorrect).
-
Adding prediction to the Branch-Target Buffer:
-
Suppose we add
2-bits
of prediction (the purpose of the last field in the previous figure.)
-
Then, by definition, the branch is predicted taken (since it has an entry in the BTB) even if the predictor indicates that it should NOT be taken.
-
In this case, it is better to have
separate buffers
for prediction and predicted PCs (which can be different sizes).
-
A "not taken" in the prediction buffer will override an entry in the BTB.
-
Steps in handling an instruction with a Branch-Target Buffer.
-
Variation on Branch-Target Buffer:
Branch folding
-
Instead of storing just the branch address, the BTB can store the
actual instruction
as well.
-
It could then
return the new instruction
from the cache rather than just the new address.
-
In this way, the branch "disappears" since it is replaced with the instruction given by its target address.
-
The branch instruction does NOT require any execution cycles !
-
Of course, if it's a conditional branch, we will still have to make sure the condition is satisfied.
-
But this can work very well for:
-
Unconditional branches
-
Conditional branches where the condition is easy to test (condition codes).
-
Misprediction rate
-
One obvious limit to the benefits of branch prediction is the misprediction rate.
-
If it's too high, there is too little benefit to justify the added hardware.
-
Misprediction penalties
-
Just as important are the penalties for misprediction.
-
If these are no worse than the standard penalties for missed static prediction, dynamic prediction is a win.
-
But what if
dynamic
misprediction penalties are worse than
static
misprediction penalties?
-
Then,
static
prediction might actually outperform
dynamic
prediction even though it has a worse misprediction rate.