-
So far, we've discussed techniques for lowering ideal CPI to as close to 1 as possible.
-
In order to go
below
1, though, the CPU must be capable of issuing more than one instruction per cycle.
-
This can be done in two ways:
-
Superscalar
-
In superscalar architectures, the processor tries to issue
more than one
instruction per cycle so as to keep all of the functional units busy.
-
There may be limitations on parallel issue, i.e.
-
No more than one memory instruction per clock cycle.
-
A limit of a single branch per cycle.
-
In order to maximize the number of instructions issued per clock, both
static
and
dynamic
scheduling techniques are used.
-
VLIW
-
In contrast, VLIW (Very Long Instruction Word) processors issue a
fixed
number of instructions per clock.
-
It's similar to taking (for example) four DLX instructions and turning them into one 128 bit instruction.
-
VLIW processors are inherently
statically
scheduled by the compiler.
-
We'll need to make sure that there are
no data
and
structural
hazards between instructions issued together.
-
The easiest way to accomplish this is to allow
dual issue
of one integer instruction (ALU, load/store) and one floating point instruction.
-
Hardware requirements
-
Instruction alignment
-
We can require that instruction pairs be 64-bit aligned, and that the integer instruction be first.
-
We could relax this requirement, but it would increase the complexity of detecting hazards and thus the cost of the hardware.
-
Arithmetic units & pipelines
-
The CPU must have sufficient FP hardware to support one issue/clk.
-
-
This means pipelined FP units (or multiple FP units or both).
-
Hardware requirements
-
Interactions between integer and FP
-
FP and integer are largely independent.
-
However, integer instructions such as FP loads and stores as well as movement between integer and FP registers can cause problems.
-
These create contention for the
FP register ports
and
RAW
hazards
between integer FP loads/stores and FP ALU instructions.
-
The first can be handled by adding an extra port to the FP register file for memory operations.
-
Therefore, we must detect the case in which an
FP ALU
instruction is issued in the same cycle as the
load
that fetches a source operand for it (RAW hazard.)
-
Data and control hazards
-
In the simple DLX pipeline, loads had a latency of one clk cycle.
-
In the superscalar pipeline, the result of a load cannot be used on the
same clk
or the next clk cycle.
-
Hazards impose a penalty measured
in cycles
, not
instructions
.
-
This means the next 3 instructions cannot use the result without a stall.
-
The same is true for branch delays.
-
Therefore, more ambitious compiler or hardware scheduling techniques and more complex instruction decoding (for branches) is needed.
-
If the CPU is not able to get a useful instruction in one of the two slots, the CPI increases and approaches 1.
-
Static scheduling
on a superscalar processor:
-
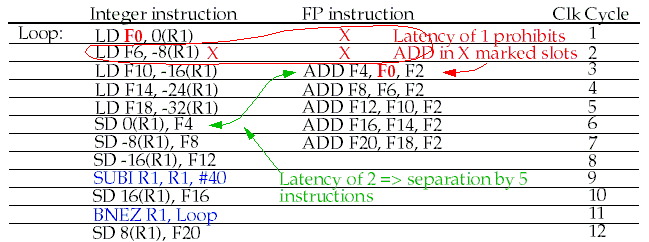
Loop unrolling
and scheduling on a dual-issue DLX:
-
To schedule without delays, 5 copies unrolled. 2.4 clks per iteration.
-
Dynamic scheduling
on a superscalar processor:
-
Dynamic scheduling can improve on these results to an even greater extent.
-
This is true because the CPU can dual issue instructions with dependencies and serialize them later using hazard detection logic.
-
Additional hardware can reduce delays through the elimination of
WAR
and
WAW
hazards and memory disambiguation (as we saw with Tomasulo's approach.)
-
Dynamic scheduling allows the CPU to keep the functional units busy as often as possible.
-
It also permits the CPU to run well on code that was not scheduled for superscalar execution.
-
Superscalar machines use hardware to reorder instructions and keep functional units busy.
-
With
VLIW
(Very Long Instruction Word) machines, all of this burden falls upon the compiler.
-
Each VLIW "instruction" is composed of multiple independent instructions, each of which execute on different function units.
-
The functional units might include integer ALUs, FP ALUs, memory units, and a branch unit.
-
To control these units, the instruction must allocate 16 or more bits to each unit to describe the operation that the unit will run on each cycle.
-
To keep the functional units busy, parallelism is uncovered by the compiler by unrolling loops and scheduling code
across
basic blocks.
-
The CPU can also help by providing forwarding.
-
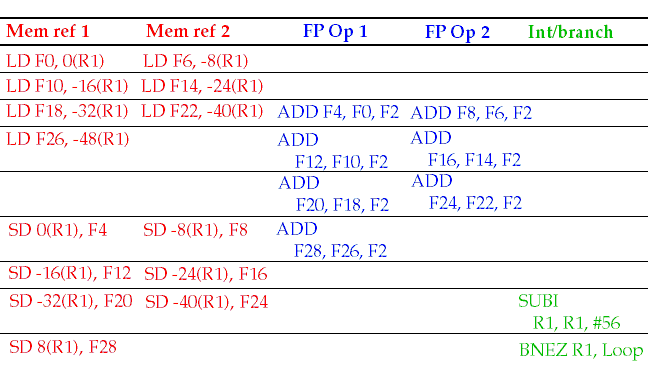
Suppose we have a VLIW machine that could issue
two
memory references,
two
FP operations and
one
integer operation or branch instruction per clock:
-
Loop unrolled
seven
times, branch delay ignored. 2.5 operations per clk.
-
Limits in multiple-issue processors:
-
Why stop at 5 instructions/clk, why not 50 !
-
Limits on available ILP in programs
-
There are usually not enough operations to fill all of the available slots.
-
It might seem that 5 independent instructions are sufficient in our example.
-
However, the memory, branch and FP units will likely be pipelined and have a multicycle latency, i.e.,
-
Assume a latency of 6 clks for the FP units, and that two FP pipelined units are available.
-
This requires that we find 12 FP instructions that are independent of the most recently issued FP instruction !
-
If a branch requires just a one cycle latency, it results in a 5 instruction latency in our machine.
-
Hardware complexity
-
Additional functional units
-
We must duplicate the integer and FP units for multiple-issue but their cost scales linearly.
-
Added bandwidth to registers and memory
-
More register file ports are required to sustain the multiple issue.
-
For example, a single integer pipeline requires 3 ports to a register file.
-
Adding another pipeline requires 3 more ports.
-
A more significant problem is adding memory ports, which are much more expensive than register ports.
-
The complexity and access time penalties of a multiported memory hierarchy are probably the most serious hardware limitations of superscalar and VLIW.
-
Hardware complexity
-
Scheduling hardware
-
This can range from pretty simple (VLIW) to very complex (superscalar).
-
Complex hardware slows the CPU down (longer cycle time) and makes it difficult to:
-
Verify the design.
-
To include fast functional units and large caches.
-
Limitations specific to superscalar or VLIW
-
Superscalar
-
Instruction issue logic is the primary challenge with superscalar.
-
VLIW
-
Technical problems:
-
Increase in code size
from open slots (wasted bits for unused functional units) increases memory bandwidth requirements unnecessarily.
-
-
A stall (i.e., cache miss) in any functional unit causes the entire processor to stall because of the
lock step
operation of VLIW.
-
Logistical problems:
-
Binary compatibility
is a problem since machines with different numbers of issues and functional unit latencies require different versions of the code.