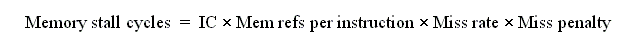-
The principle of locality says that programs do NOT access code and data uniformly.
-
Also, smaller hardware is faster, and faster hardware is more expensive.
-
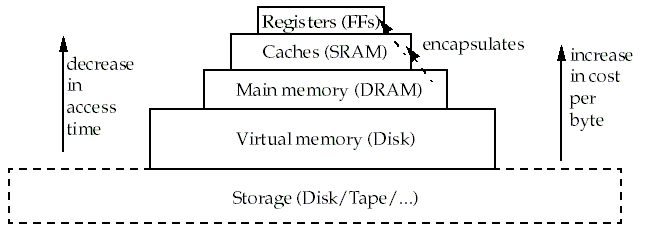
This has led to a
memory hierarchy
:
-
Performance enhancements are realizable by keeping frequently used code/data in fast memory and the rest in slower memory.
-
Four questions can be posed about
any 2 levels
of the memory hierarchy:
-
Where can a block be placed in the upper level ?
-
How is a block found if it is in the upper level ?
-
Which block should be replaced on a miss ?
-
What happens on a write ?
-
We'll focus on the interface between static and dynamic RAM (the CPU's memory cache) and dynamic RAM and disk (virtual memory).
-
A formula to evaluate the effectiveness of the memory hierarchy:
-
We will use a related formula to evaluate the performance of various memory system configurations.
-
There are several factors in this equation:
-
IC * Mem refs per instruction
-
This is the frequency with which the CPU uses memory.
-
A memory system that need only satisfy 1-2 references per cycle is easier to build than one that satisfies 4-5.
-
Miss rate
-
This is the fraction of references that are not satisfied in the upper level.
-
They require an access to the lower, slower level to be satisfied.
-
Miss penalty
-
The penalty is the length of time it takes to access the lower level.
-
A low miss rate is not much help if the miss penalty is very high.
-
If the term
cache
is used without any modifiers, it usually means the fast memory closest to the CPU.
-
Recently,
cache
has been used for everything from files to WWW pages.
-
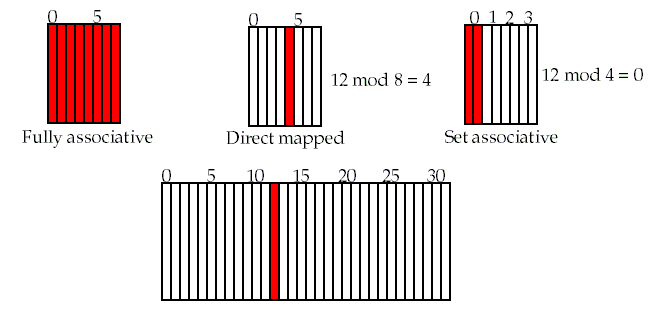
Block Placement
: Three possibilities:
-
Direct mapped
-
Block can only go in one place in the cache (usually
address
MOD
number of blocks
in cache).
-
Fully associative
-
Block can go anywhere in cache.
-
Set associative
-
Block can go in one of a
set
of places in the cache.
-
A
set
is a group of blocks in the cache.
-
-
In a set-associative cache, a block is first mapped to a set by using
block address
MOD
number of sets
in the cache.
-
A block may then be placed anywhere in that set.
-
If
sets
have
n
blocks, the cache is said to be
n-way
set associative.
-
Note that direct mapped is the same as
1-way
set associative, and fully associative is
m-way
set-associative (for a cache with m blocks).
-
Block Identification
: Finding data in the cache.
-
Components of an address as they relate to the cache:
-
Block offset
-
The first few bits of the address give the offset of the byte within a block.
-
Block address (index)
-
Used to pick a set from the cache.
-
Tag
-
Only the tag is stored in the cache.
-
All tags within a set are searched in parallel.
-
Valid bit
-
Indicates that the block in this location contains valid data.
-
Otherwise, a random sequence of bits could be mistaken for a valid entry that matched the tag.
-
Block Replacement:
Which block is replaced ?
-
This only applies to fully associative and set associative caches.
-
For direct mapped, each block can only go in one location.
-
Random
-
Choose a block from the set at random.
-
LRU
-
Choose the least-recently used block.
-
Replace the block that has been unused for the longest time.
-
This requires extra bits in the cache to keep track of accesses.
-
It turns out that LRU isn't much better than random replacement.
-
Write Strategy
: What happens on a write ?
-
All instruction access are reads and most data accesses are reads (DLX, 9% stores and 26% loads).
-
Making the common case fast means optimizing caches for reads.
-
The common case is also the easy case to handle since tag checking and reading can occur in
parallel
.
-
Plus, extra bytes read can be ignored.
-
However, Amdahl's law reminds us that we cannot ignore writes.
-
Problem: Tag checking and writing can NOT occur in parallel.
-
Therefore, writing is usually slower than reading.
-
Plus, extra bytes can NOT be written.
-
Write policy
-
This determines what happens when a block is written to the cache, and when the write is communicated to the lower level (main memory).
-
Write-through
-
In this scheme, the block is written both to the cache and main memory.
-
Write back
(also
copy back
)
-
In this scheme, only the block in cache is modified.
-
Main memory is modified when the block must be replaced in the cache.
-
This requires the use of a
dirty bit
to keep track of which blocks have been modified.
-
Write-through adv: Read misses don't result in writes, memory hierarchy is consistent and it is simple to implement.
-
Write back adv: Writes occur at speed of cache and main memory bandwidth is smaller when multiple writes occur to the same block.
-
Write misses
-
If a miss occurs on a write (the block is not present), there are two options.
-
Write allocate
-
The block is loaded into the cache on a miss before anything else occurs.
-
Write around
(no write allocate)
-
The block is only written to main memory
-
It is not stored in the cache.
-
In general,
write-back
caches use
write-allocate
, and
write-through
caches use
write-around
.
-
This is true in the former case because it is hoped that subsequent writes to that block will be captured by the cache.
-
In the latter case, subsequent writes to that block will still go to memory.
-
Write buffers
-
To avoid stalling on writes, many CPUs use a write buffer.
-
A small cache that can hold a few values waiting to go to main memory.
-
This buffer helps when writes are clustered.
-
It does not entirely eliminate stalls since it is possible for the buffer to fill if the burst is larger than the buffer.
-
Write merging
-
Blocks are often larger than a machine word.
-
Many write buffers can
merge
memory writes to save both write buffer space and memory traffic.
-
For example, two writes to the same location can be collapsed or, two writes to sequential locations can be merged into a single buffer space.
-
Split vs. unified caches
-
Unified cache
-
All memory requests go through a single cache.
-
This requires less hardware, but also has lower bandwidth and more opportunity for collisions.
-
Split I & D cache
-
A separate cache is used for instructions and data.
-
This uses additional hardware, though there are some simplifications (the I cache is read-only).
-