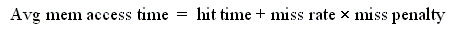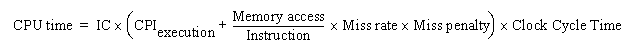-
Average memory access time is a useful measure to evaluate the performance of a memory-hierarchy configuration.
-
It tells us how much penalty the memory system imposes on each access (on average).
-
It can easily be converted into clock cycles for a particular CPU.
-
But leaving the penalty in nanoseconds allows two systems with
different clock cycles times
to be compared to a single memory system.
-
There may be different penalties for Instruction and Data accesses.
-
In this case, you may have to compute them separately.
-
This requires knowledge of the fraction of references that are instructions and the fraction that are data.
-
The text gives 75% instruction references to 25% data references.
-
We can also compute the write penalty separately from the read penalty.
-
This may be necessary for two reasons:
-
Miss rates are different for each situation.
-
Miss penalties are different for each situation.
-
Treating them as a single quantity yields a useful CPU time formula:
-
Compare the performance of a
64KB unified
cache with a split cache with
32KB data
and
16KB instruction
.
-
The miss penalty for either cache is 100 ns, and the CPU clock runs at 200 MHz.
-
Don't forget that the cache requires an extra cycle for load and store hits on a unified cache because of the structural conflict.
-
Calculate the effect on
CPI
rather than the average memory access time.
-
Assume miss rates are as follows (Fig. 5.7 in text):
-
64K Unified cache: 1.35%
-
16K instruction cache: 0.64%
-
32K data cache: 4.82%
-
Assume a data access occurs once for every 3 instructions, on average.
-
The solution is to figure out the penalty to CPI separately for instructions and data.
-
First, we figure out the miss penalty in terms of clock cycles: 100 ns/5 ns = 20 cycles.
-
For the unified cache, the per-instruction penalty is (0 + 1.35% x 20) =
0.27
cycles.
-
For data accesses, which occur on about 1/3 of all instructions, the penalty is (1 + 1.35% x 20) = 1.27 cycles per access, or
0.42
cycles per instruction.
-
The total
penalty
is
0.69 CPI
.
-
In the split cache, the per-instruction penalty is (0 + 0.64% x 20) =
0.13
CPI.
-
For data accesses, it is (0 + 4.82% x 20) x (1/3) =
0.32
CPI.
-
The total
penalty
is
0.45 CPI
.
-
In this case, the split cache performs better because of the lack of a stall on data accesses.
-
Low CPI machines suffer more relative to some fixed CPI memory penalty.
-
A machine with a CPI of 5 suffers little from a 1 CPI penalty.
-
However, a processor with a CPI of 0.5 has its execution time
tripled
!
-
Cache miss penalties are measured in cycles, not nanoseconds.
-
This means that a faster machine will stall more cycles on the same memory system.
-
Amdahl's Law raises its ugly head again:
-
Fast machines with low CPI are affected significantly from memory access penalties.
-
The increasing speed gap between CPU and main memory has made the performance of the memory system increasingly important.
-
15 distinct organizations characterize the effort of system architects in reducing average memory access time.
-
These organizations can be distinguished by:
-
Reducing the miss rate.
-
Reducing the miss penalty.
-
Reducing the time to hit in a cache.
-
Components of miss rate: All of these factors may be reduced using various methods we'll talk about.
-
Compulsory
-
Cold start misses
or
first reference misses
: The first access to a block can NOT be in the cache, so there must be a compulsory miss.
-
These are suffered regardless of cache size.
-
Capacity
-
If the cache is too small to hold all of the blocks needed during execution of a program, misses occur on blocks that were discarded earlier.
-
In other words, this is the difference between the compulsory miss rate and the miss rate of a finite size fully associative cache.
-
Conflict
-
If the cache has sufficient space for the data, but the block can NOT be kept because the set is full, a conflict miss will occur.
-
This is the difference between the miss rate of a non-fully associative cache and a fully-associative cache.
-
These misses are also called
collision
or
interference
misses.
-
To reduce cache miss rate, we have to eliminate some of the misses due to the three C's.
-
We cannot reduce
capacity
misses much except by making the cache larger.
-
We can, however, reduce the
conflict
misses and
compulsory
misses in several ways:
-
Larger cache blocks
-
Larger blocks decrease the compulsory miss rate by taking advantage of spatial locality.
-
However, they may increase the miss penalty by requiring more data to be fetched per miss.
-
In addition, they will almost certainly increase
conflict
misses since fewer blocks can be stored in the cache.
-
And maybe even
capacity
misses in small caches.
-
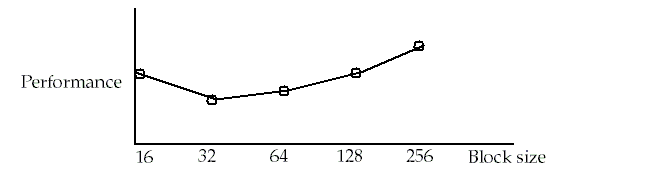
The performance curve is U-shaped because:
-
Small blocks have a higher miss rate and
-
Large blocks have a higher miss penalty (even if miss rate is not too high).
-
High latency
,
high bandwidth
memory systems encourage large block sizes since the cache gets more bytes per miss for a small increase in miss penalty.
-
32-byte blocks are typical for 1-KB, 4-KB and 16-KB caches while 64-byte blocks are typical for larger caches.
-
Higher associativity
-
Conflict
misses can be a problem for caches with low associativity (especially direct-mapped).
-
2:1 cache rule of thumb
: a direct-mapped cache of size N has the same miss rate as a 2-way set-associative cache of size N/2.
-
However, there is a limit -- higher associativity means more hardware and usually longer cycle times (increased hit time).
-
In addition, it may cause more capacity misses.
-
Nobody uses more than 8-way set-associative caches today, and most systems use 4-way or less.
-
The problem is that the higher hit rate is offset by the slower clock cycle time.
-
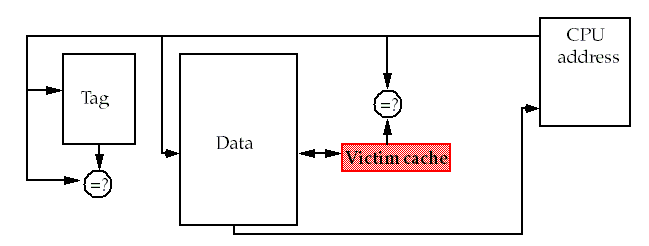
Victim caches
-
A victim cache is a small (usually, but not necessarily) fully-associative cache that holds a few of the most recently replaced blocks or
victims
from the main cache.
-
Can improve miss rates without affecting the processor clock rate.
-
This cache is checked on a miss before going to main memory.
-
If found, the victim block and the cache block are swapped.
-
Victim caches
-
It can reduce
capacity
misses but is best at reducing
conflict
misses.
-
It's particularly effective for small, direct-mapped data caches.
-
A 4 entry victim cache handled from 20% to 95% of the conflict misses from a 4KB direct-mapped data cache.
-
Pseudo-associative caches
-
These caches use a technique similar to double hashing.
-
On a miss, the cache searches a different
set
for the desired block.
-
The second (
pseudo
) set to probe is usually found by inverting one or more bits in the original set
index
.
-
Note that two separate searches are conducted on a miss.
-
The first search proceeds as it would for direct-mapped cache.
-
Since there is no associative hardware, hit time is fast if it is found the first time.
-
Pseudo-associative caches
-
While this second probe takes some time (usually an extra cycle or two), it is a lot faster than going to main memory.
-
The secondary block can be swapped with the primary block on a "slow hit".
-
This method reduces the effect of
conflict
misses.
-
Also improves miss rates without affecting the processor clock rate.
-
Hardware prefetch
-
Prefetching is the act of getting data from memory before it is actually needed by the CPU.
-
Typically, the cache requests the next consecutive block to be fetched with a requested block.
-
It is hoped that this avoids a subsequent miss.
-
Hardware prefetch
-
This reduces
compulsory
misses by retrieving the data before it is requested.
-
Of course, this may increase other misses by removing useful blocks from the cache.
-
Thus, many caches hold prefetched blocks in a
special buffer
until they are actually needed.
-
This buffer is faster than main memory but only has a limited capacity.
-
Prefetching also uses main memory bandwidth.
-
It works well if the data is actually used.
-
However, it can adversely affect performance if the data is rarely used and the accesses interfere with `demand misses'.