-
Compiler-controlled prefetch
-
An alternative to hardware prefetching.
-
Some CPUs include
prefetching instructions
.
-
These instructions request that data be moved into either a register or cache.
-
These special instructions can either be
faulting
or
non-faulting
.
-
Non-faulting instructions do nothing (no-op) if the memory access would cause an exception.
-
Of course, prefetching does
not
help if it interferes with normal CPU memory access or operation.
-
Thus, the cache must be
nonblocking
(also called
lockup-free
).
-
This allows the CPU to overlap execution with the prefetching of data.
-
Compiler-controlled prefetch
-
While this approach yields better prefetch "hit" rates than hardware prefetch, it does so at the expense of executing more instructions.
-
Thus, the compiler tends to concentrate on prefetching data that are likely to be cache misses anyway.
-
Loops are key targets since they operate over large data spaces and their data accesses can be inferred from the loop index in advance.
-
Compiler optimizations
-
This method does NOT require any hardware modifications.
-
Yet it can be the most efficient way to eliminate cache misses.
-
The improvement results from better code and data organizations.
-
For example, code can be rearranged to avoid conflicts in a direct-mapped cache, and accesses to arrays can be reordered to operate on
blocks of data
rather than processing
rows
of the array.
-
Compiler optimizations
-
Merging arrays
-
This method combines two separate arrays (that might conflict for a single block in the cache) into a single interleaved array.
-
This brings together corresponding elements in both arrays, which are likely to be referenced together.
-
Reorganizing and fetching them at the same time can reduce misses.
-
This technique reduces misses by improving spatial locality.
-
Compiler optimizations
-
Loop interchange
-
By switching the order in which loops execute, misses can be reduced due to improvements in spatial locality.
-
These loops cause a miss on each memory access because of the long
stride
given by index j in the inner loop.
-
By switching the order of the loops, the stride is changed to 1, allowing the elements to be accessed in sequential order.
-
Compiler optimizations
-
Loop Fusion
-
Many programs have separate loops that operate on the same data.
-
Combining these loops allows a program to take advantage of
temporal locality
by grouping operations on the same (cached) data together.
-
Blocking
-
The above methods work well on array accesses that occur along one dimension only.
-
However, loops that access both rows and columns, such as matrix multiplication, are problems.
-
Blocking
-
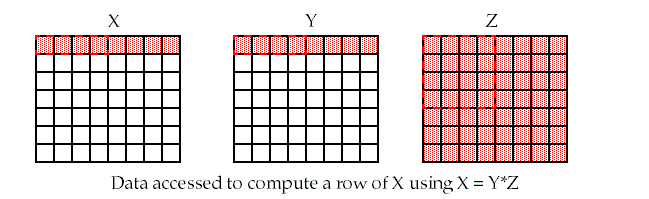
Unoptimized matrix multiplication requires the cache to hold the minimum elements shown shaded below.
-
Capacity misses can occur for large matrices since it may not be possible to store all the elements of Z in the cache.
-
Blocking operates on blocks (submatrices) as shown by the dotted line, and reduces the total number of memory words accessed by a factor of B (the blocking factor).
-
Compiler optimizations
-
Blocking
-
Therefore, matrix multiplication is performed by multiplying the submatrices first.
-
Matrix Y benefits from spatial locality and Z benefits from temporal locality.
-
This method is also used to reduce the number of blocks that must be transferred between disk and main memory.
-
Therefore, the technique is effective for several levels of the hierarchy.
-
Given the increasing speed gap in processor speed and memory access times, these last two techniques will only increase in importance over time.
-
Giving read misses priority
-
If a system has a write buffer, writes can be delayed to come after reads.
-
The system must, however, be careful to check the write buffer to see if the value being read is about to be written.
-
A simple method of dealing with this problem:
-
Stall reads until the write buffer is empty.
-
However, this method increases the read miss penalty considerably since the write buffer in write-through is likely to have blocks waiting to be written.
-
An alternative is to check the write buffer for conflicts.
-
In cases like this, the write buffer acts as a victim cache.
-
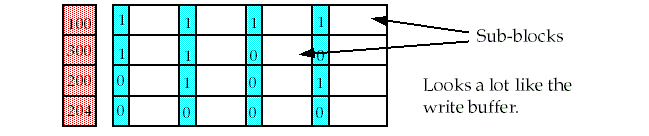
Using subblocks to reduce fetch time
-
Tags can hurt performance by occupying too much space or by slowing down caches.
-
Using large blocks reduces the amount of storage for tags (and makes them shorter), optimizing space on the chip.
-
This may even reduce
miss rate
by reducing compulsory misses.
-
However, the
miss penalty
for large blocks is high, since the entire block must be moved between the cache and memory.
-
The solution is to divide each block into subblocks, each of which has a valid bit.
-
Using subblocks to reduce fetch time
-
The tag is valid for the entire block, but only a sub-block needs to be read on a miss.
-
Therefore, a block can no longer be defined as the minimum unit transferred between cache and memory.
-
This results in a smaller miss penalty.
-
Early restart & critical word first
-
This strategy does NOT require extra hardware (like the previous two techniques).
-
It optimizes the order in which the words of a block are fetched and when the desired word is delivered to the CPU.
-
-
Early restart
-
With early restart, the CPU gets its data (and thus resumes execution) as soon as it arrives in the cache without waiting for the rest of the block.
-
Early restart & critical word first
-
Critical word first
-
Instead of starting the fetch of a block with the first word, the cache can fetch the requested word first and then fetch the rest afterwards.
-
In conjunction with
early restart
, this reduces the miss penalty by allowing the CPU to continue execution while most of the block is still being fetched.
-
Nonblocking caches
-
A
nonblocking
cache, in conjunction with out-of-order execution, can allow the CPU to continue executing instructions after a data cache miss.
-
The cache continues to supply hits while processing read misses (
hit under miss
).
-
The instruction needing the missed data waits for the data to arrive.
-
Nonblocking caches
-
Complex caches can even have multiple outstanding misses (
miss under miss
).
-
But this greatly increases cache complexity.
-
Second-level caches
-
This method focuses on the interface between the cache and main memory.
-
We can add an second-level cache between main memory and a small, fast first-level cache.
-
This helps satisfy the desire to make the cache fast and large.
-
The second-level cache allows:
-
The smaller first-level cache to fit on the chip with the CPU and fast enough to service requests in one or two CPU clock cycles.
-
Hits for many memory accesses that would go to main memory, lessening the effective miss penalty.
-
Second-level caches
-
Performance of a multi-level cache:
-
The performance of a two-level cache is calculated in a similar way to the performance for a single level cache.
-
So the miss penalty for level 1 is calculated using the hit time, miss rate, and miss penalty for the level 2 cache.
-
For two level caches, there are two miss rates:
-
Global miss rate
-
The number of misses in the cache divided by the total number of memory accesses generated by the CPU (Miss rateL1*Miss rateL2).
-
Local miss rate
-
The number of misses in the cache divided by the total number of memory accesses to this cache (Miss rateL2 for the 2nd-level cache).
-
Performance of a multi-level cache:
-
Note that the local miss rate for L2 is high because it's only getting the misses from the L1 cache (instead of all memory accesses).
-
In general, the global miss rate is a more useful measure since it indicates what fraction of the memory accesses that leave the CPU go all the way to memory.
-
Desirable characteristics for an L2 cache:
-
Much larger than the L1 cache
-
Since L2 contains the same data as L1, making L2 about the same size as L1 causes it to have a high local miss rate.
-
This is true since if we miss in L1, it is likely that we'll miss in L2 as well resulting in performance that is not much better than using main memory alone.
-
Therefore, it must be much larger.
-
Desirable characteristics for an L2 cache:
-
Higher associativity
-
The main reason for low associativity was fast, small caches.
-
The L2 cache need be
neither
, and will benefit from the higher hit rate that more blocks per set provides.
-
Larger block size
-
This has the advantage of reducing compulsory misses that must go all the way to main memory.
-
Since the L2 cache is large, the effect of increasing conflict misses (as is true for a smaller cache) is minimal.
-
Inclusion
-
If all of the data in the L1 cache is also in the L2 cache, the L2 cache has the
multilevel inclusion property
.
-
Most caches enforce this property since it is easier to deal with cache consistency.
-
Consistency between I/O and caches (and between caches in a multiprocessor) can be determined by checking second-level cache.
-
Design of L1 and L2 caches
-
Although they can be designed separately, it is often helpful to know if there is going to be an L2 cache.
-
For example,
write-through
in L1 is much more effective if there is an L2
writeback
cache to buffer repeated writes.
-
Similarly, a direct-mapped L1 cache can work fine if the L2 cache satisfies most of the conflict misses.
-
L2 cache summary
-
In general, cache design trades fast hits for few misses.
-
For an L1 cache, fast hits are more important.
-
For L2, there are many fewer hits, so fewer misses becomes more important.
-
Therefore,
larger
caches with
higher associativity
and
larger blocks
are beneficial in L2 caches.