-
Are we reaching performance limits in uniprocessors ?
-
Remember, performance enhancements are realized through improvements in both:
-
Architecture
-
Technology
-
Panel session at VTS'99: "The end of Moore's Law era?"
-
Three say yes (within 10 years), two say no.
-
Jury is still out on this one.
-
However, it is generally believed that the physics of the process, e.g. the size of an atom, will impose a hard limit.
-
With reference to Moore's law:
-
"All exponentials in nature eventually saturate."
-
What is the scaling factor of the x-axis and where are we today on the curve?
-
What about improvements in architecture?
-
We've been talking about these for 12 weeks now.
-
However,
parallel machines
appear to be a natural candidate as a successor to the uniprocessor:
-
A cost effective way to improve performance beyond the uniprocessor is by connecting multiple
microprocessors
together.
-
It is
un
likely that architectural innovations can be sustained indefinitely (analogous to the physical laws that limit technology except in reference to complexity).
-
There has been steady progress on the major obstacle to widespread use of parallel machines, namely
software
.
-
We will focus on the mainstream of multiprocessor design.
-
Machines with small to medium numbers of processors (<100).
-
Viable future architectures with more than 100 processors is difficult to predict.
-
Flynn's classification based on the parallelism in the instruction and data streams:
-
SISD (Single instruction stream, single data stream)
.
-
SIMD (Single instruction stream, multiple data streams)
.
-
The same instruction is executed by multiple processors using different data streams.
-
Each processor has its own data memory.
-
Only a
single
instruction memory and control processor which fetches and dispatches instructions.
-
MISD (Multiple instruction streams, single data stream)
.
-
No commercial machine has been built.
-
MIMD (Multiple instruction streams, multiple data streams)
.
-
Each processor fetches its own instructions and operates on its own data.
-
Often built using off-the-shelf microprocessors.
-
SIMD
model was popular through the 80s.
-
MIMD
model has clearly emerged as the architecture of choice in recent years.
-
MIMD offers flexibility
.
-
Can operate as a single-user machine providing high performance for one application.
-
Can operate as multiprogrammed machines running many tasks simultaneously.
-
MIMDs can build on the cost/performance advantages of off-the-shelf microprocessors
.
-
Existing
MIMD
machines fall into two classes:
-
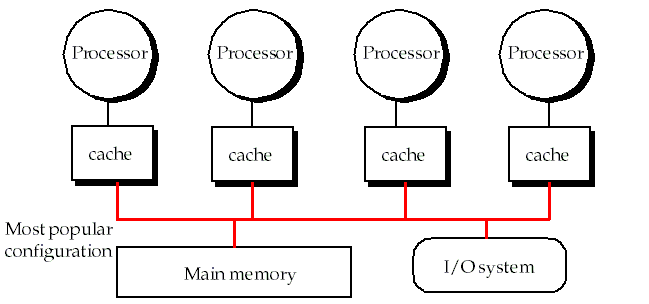
Centralized shared-memory architectures
(
Uniform Memory Access or UMA
).
-
At most a few dozen processors which share a bus and a single main memory.
-
Large caches allow the bus and memory organization to satisfy the memory demands of a small number of processors.
-
Distributed memory architectures
.
-
Supports larger processor counts by distributing the memory and allowing multiple memories to work in parallel.
-
With
increases
in processor bandwidth requirements, the number of processors for which this scheme is preferred (over centralized) is
decreasing
.
-
Distributing the memory among the nodes has two major
advantages
:
-
It is a cost-effective way to
scale
the memory bandwidth (if most accesses are to local memory in the node).
-
It reduces the latency for accesses to local memory (due to less contention).
-
Disadvantage:
-
Communicating data between processors becomes more complex and has higher latency.
-
Key characteristics that distinguish distributed memory machines:
-
How communication is performed.
-
The architecture of the distributed memory.
-
Distributed shared-memory
(DSM) architectures:
-
Physically separate memories can be addressed as one logically shared address space.
-
The address space is shared --
all processors see the same address space
.
-
These machines are referred to as NUMA (non-uniform memory access) in contrast to the centralized UMA machines.
-
Multicomputer architecture
:
-
Multiple private address spaces that are logically disjoint and cannot be addressed by a remote processor.
-
These address space organizations have an associated
communication mechanism
.
-
For DSM,
shared memory
can be used to communicate data via load and store operations.
-
For the multicomputer arrangement, communication is done by
message passing
using either synchronous (RPC) or asynchronous mechanisms.
-
Three performance metrics are critical in any
communication mechanism
:
-
Communication bandwidth.
-
Bisection bandwidth is the bandwidth across the "narrowest" part of the interconnection network.
-
Bandwidth in and out of an individual processor is also important.
-
It is affected by the architecture within the node and by the communication mechanism.
-
With respect to the mechanism, when communication occurs, resources are tied up or occupied, preventing other communication.
-
Occupancy
can limit the communication bandwidth.
-
Communication latency.
-
Lower is better of course.
-
Is equal to:
-
Time of flight
is preset and
transport latency
is determined by interconnection network.
-
Sender and receiver overhead are determined by communication mechanism.
-
Complex mechanisms (i.e. for naming and protection) increase latency, particularly those that require the OS.
-
Latency affects performance either by:
-
Causing the processor to wait.
-
Tying up processor resources.
-
Communication latency hiding.
-
How well can the mechanism hide latency by overlapping communication with computation or with other communication ?
-
For example, a system that only allows access to a word at a time may have low latency.
-
But it may be unable to hide the latency (each word transferred is treated as a cache miss).
-
Another machine may have a higher latency but allow the processor to do other things while waiting for data.
-
We'll see examples of latency hiding techniques for shared memory later.
-
Latency hiding is more difficult to measure than the previous two and is application dependent.
-
These performance measures are affected by:
-
The
size
of the data items being communicated by the application.
-
It affects the latency and bandwidth in a direct way.
-
And the effectiveness of the different latency hiding techniques.
-
The
regularity
in the communication patterns.
-
These affect the cost of naming and protection (communication overhead).
-
Ideally, we would like a mechanism that performs well with:
-
Large and small data requests.
-
Regular and irregular communication patterns.
-
Shared-memory advantages:
-
Compatibility
with well-understood mechanisms in use in centralized multiprocessors.
-
Ease of programming
, particularly for systems in which communication patterns are complex or vary dynamically during execution.
-
Low overhead
for communication (hardware used to enforce protection).
-
The ability to use
hardware-controlled caching
(which reduces the frequency of remote communication).
-
Message-passing advantages:
-
Simpler hardware
(especially with respect to building coherent caches).
-
Explicit communication
forces programmers and compiler writers to pay attention to what is costly and what is not.
-
Is this really an advantage ?
-
Shared-memory communication is the much more popular today.
-
Centralized schemes still dominate, but long term trends favor distributing memory.
-
Insufficient parallelism
: Amdahl's law applies to parallel processing as well.
-
Any program has a parallel portion and a serial portion.
-
The parallel portion is the only part that is sped up by having multiple processors.
-
As with uniprocessors, speedup is limited by the fraction of the original program that can be parallelized.
-
For example, suppose we want to achieve a
speedup of 80
with 100 processors. What is the fraction of the original computation that can be sequential ?
-
With simplifying assumptions (see text):
-
The second major challenge involves the
large latency of remote memory access
.
-
This may cost anywhere from 50 clocks to 10,000 clocks !
-
Dependent on:
-
The communication mechanism.
-
The type of interconnection network.
-
The scale of the machine.
-
Insufficient parallelism
can be attacked in software with new algorithms that have better parallel performance.
-
Long communication latency
can be attacked by the architecture (caching) or the programmer (restructuring the data).
-
We focus on techniques for reducing the impact of long communication latency.