The use of large multilevel caches can substantially reduce memory bandwidth demands of a processor.
This has made it possible for several (micro)processors to share the same memory through a shared bus.
Caching supports both
private
and
shared
data.
For private data, once cached, it's treatment is identical to that of a uniprocessor.
For shared data, the shared value may be replicated in many caches.
Replication has several advantages:
Reduced latency
and
memory bandwidth
requirements.
Reduced contention
for data items that are read by multiple processors simultaneously.
However, it also introduces a problem:
Cache coherence
.
Cache Coherence
With multiple caches, one CPU can modify memory at locations that other CPUs have cached.
For example:
CPU A
reads
location x, getting the value
N
.
Later, CPU B
reads
the same location, getting the value
N
.
Next, CPU A
writes
location x with the value
N - 1
.
At this point, any
reads
from CPU B will get the value
N
, while
reads
from CPU A will get the value
N - 1
.
This problem occurs both with
write-through
caches and (more seriously) with
write-back
caches.
Cache coherence
: informal definition:
A memory system is coherent if any read of a data item returns the most recently written value of that data item.
Upon closer inspection, there are several aspects that need to be addressed.
Cache Coherence
Coherence defines what values can be returned by a read.
A memory system is coherent if:
Read after write works for a single processor.
If CPU A writes N to location X, all future reads of location X will return N if no other processor writes location X after CPU A.
Other processors' writes eventually propagate.
If CPU A writes value N to location X, CPU B
will eventually
be able to read value N from location X.
Once it does so, it will continue to read value N until location X is written again.
This is our intuitive notion of a coherent view of memory.
Cache Coherence
Writes to a single location are serialized.
If CPUs A and B both write to location X, all processors
see
the same order of the writes.
This does not mean that all reads must return the same value.
If value N1 is written "first" to location X, followed closely by reads of X and a write of X with value N2, some reads may return N1 and some N2.
However, a processor that reads N2 will return N2 for all future reads.
Consistency
:
This indicates when a modification to memory is seen by other processors (i.e. will be returned by a read).
Clearly, this can NOT be "instantaneous" since it may be that the new value has not even left the processor when a read occurs.
Cache Coherence
Consistency
:
The issue of
when
a written value MUST be seen by a reader is defined by a memory consistency model.
For now, let's assume that a write is not complete until all processors have "seen" the effect of the write.
Also, assume that a processor may not reorder memory accesses to move reads before an outstanding write.
Reads
can be reordered, but
reads
and
writes
can not be interchanged.
Coherent caches provide both:
Replication of shared data items (reduces latency and contention).
Here, the purpose is to provide multiple copies of data so that several processors can access a single piece of memory without serialization.
Migration of data items (reduces latency).
Data items are moved from one processor to another as needed.
Cache-Coherence Protocols
Small-scale multiprocessor use hardware mechanisms to track the state of data blocks that are shared.
Two classes of protocols:
Directory based.
The sharing status of a block of physical memory is kept in one location (the directory).
Snooping.
The sharing status is distributed and kept with the block in each cache.
The caches are usually on a shared memory bus.
The cache controllers snoop the bus to watch for transactions that occur on data blocks that they hold.
Bus Snooping Protocols
Write invalidate.
It is the most common protocol, both for snooping and for directory schemes.
The basic idea behind this protocol is that writes to a location invalidate other caches' copies of the block.
Reads
by other processors on invalidated data cause cache misses.
If two processors
write
at the same time, one wins and obtains exclusive access.
Processor activity
Bus activity
Contents of CPU A's cache
Contents of CPU B's cache
Contents of mem location X
CPU A reads X
Cache miss
0
0
CPU B reads X
Cache miss
0
0
0
CPU A writes 1
Invalidate
1
0
CPU B reads X
Cache miss
1
1
1
This example assumes a
write-back
cache.
Bus Snooping Protocols
Write broadcast (write update).
An alternative is to update all cached copies of the data item when it is written.
To reduce bandwidth requirements, this protocol keeps track of whether or not a word in the cache is shared.
If not,
no
broadcast is necessary.
Processor activity
Bus activity
Contents of CPU A's cache
Contents of CPU B's cache
Contents of mem location X
CPU A reads X
Cache miss
0
0
CPU B reads X
Cache miss
0
0
0
CPU A writes 1
Broadcast
1
1
1
CPU B reads X
1
1
1
This example also assumes a
write-back
cache.
Performance Differences between Bus Snooping Protocols
Write invalidate
is much more popular.
This is due primarily to the performance differences.
Multiple writes to the same word with no intervening reads require
multiple
broadcasts.
With multiword cache blocks, each word written requires a broadcast.
For write invalidate, the first word written invalidates.
Also write invalidate
works on blocks
, while write broadcast must work on individual words or bytes.
The delay between writing by one processor and reading by another is
lower
in the write broadcast scheme.
For write invalidate, the read causes a miss.
Since bus and memory bandwidth are more important in a bus-based multiprocessor, write invalidation performs better.
Therefore, we focus on implementation of the
write invalidate
protocol.
Implementation of Write Invalidate Protocols
Write invalidate is simple in bus-based schemes.
Acquire the bus and broadcast the address to be invalidated.
Since all processors snoop the bus, they can check the address against items in their cache.
Bus acquisition also
serializes
write operations to the same memory location.
Writes to a shared data item cannot complete until the bus is acquired.
What about locating a data item when a cache miss occurs ?
For
write-through
, it's in memory.
For
write-back
, snooping can be used.
If a processor finds that it has a dirty copy of the requested cache block, it provides the block instead of memory.
Note,
write-back caches
are greatly preferred in a multiprocessor environment since they reduce memory bandwidth.
Implementation of Write Invalidate Protocol on Write-Back caches.
Writes are the issue here.
We would like to know if any other caches contain the block to be written by a processor.
If there are none, then the write need
not
be placed on the bus.
This reduces the time to complete the write and reduces memory bandwidth.
This can be tracked by adding an
extra state bit
(in addition to the valid and dirty bits) that indicates if the block is shared.
If the bit is set (the block is shared), the cache generates an invalidation on the bus and marks the block as private.
If another processor later requests the block, the miss is snooped and the "owner" sets the state bit to shared.
Implementation of Write Invalidate Protocol on Write-Back caches.
Note that every bus transaction checks cache-address tags.
This could potentially interfere with CPU cache access.
This interference can be reduced by:
Duplicating the tags.
Bus access can proceed in
parallel
with CPU access.
On misses, the processor must arbitrate for and update both sets of tags.
The same is true for the snoop (to perform an invalidate or to update the shared bit).
However, a snoop may require fetching a block.
This is the only instance that may cause a stall.
Implementation of Write Invalidate Protocol on Write-Back caches.
Employing a multilevel cache with inclusion.
Every entry in L1 is in L2.
Therefore, snooping can be directed to L2, where there are fewer processor accesses.
If a snoop gets a hit, then it must arbitrate for L1 to update state and possibly retrieve data.
This usually stalls the processor.
Since it is popular to use multi-level caches in multiprocessors (to reduce memory bandwidth), this solution is usually adopted.
It is also possible to duplicate the tags in L2 to further reduce contention.
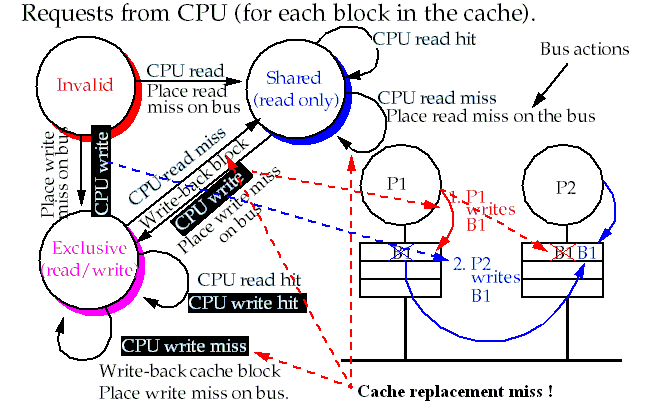
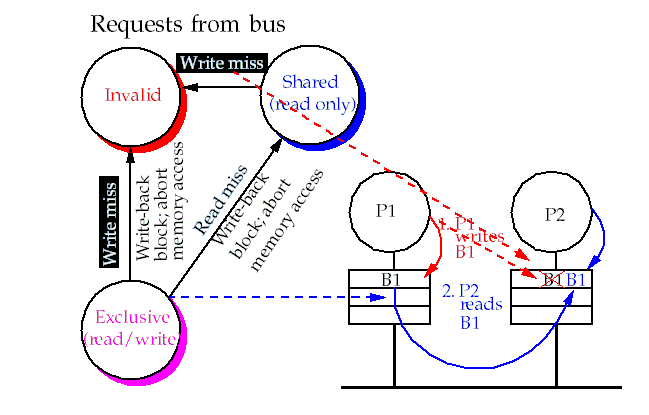
An Example Centralized Shared-Memory Snooping Protocol
Implemented by incorporating a finite state controller in each node.
The controller responds to requests from the processor and bus:
To simplify the controller, write hits and write misses to shared blocks are treated as write misses.
Request
Source
Function
Read hit
Processor
Read data in cache.
Write hit
Processor
Write data in cache.
Read miss
Bus
Request data from cache or memory.
Write miss
Bus
Request data from cache or memory (perform any needed invalidates).
This causes processors with copies to invalidate them.
An Example Centralized Shared-Memory Snooping Protocol
Write invalidation and a write-back cache assumed:
An Example Centralized Shared-Memory Snooping Protocol
These state transitions have no analog in a uniprocessor cache controller.
An Example Centralized Shared-Memory Snooping Protocol
Complications we have ignored:
Assumes that operations are
atomic
.
In reality, a write miss is not atomic -- just too much work to do.
Also, read misses on a
split transaction bus
are not atomic.
Nonatomic actions introduce the possibility that the protocol can
deadlock
.
See Appendix E for a fix.
Two major simplifications:
Real protocols distinguish between write hits and write misses.
From the shared state, a
write miss
would require the action shown previously.
However, a
write hit
does
not
require that the data be fetched since it is up-to-date.
All that is needed is an invalidate operation.
Real protocols distinguish between
shared
and
clean
data in exactly one cache.
A "clean and private" state eliminates the need to generate a bus transaction on a write to a "clean and private" block.