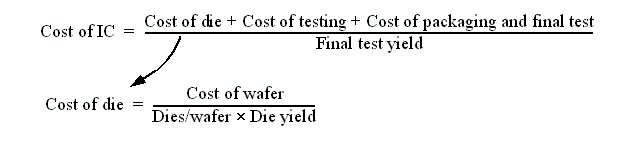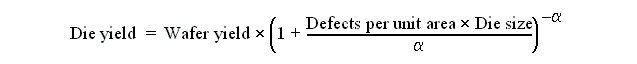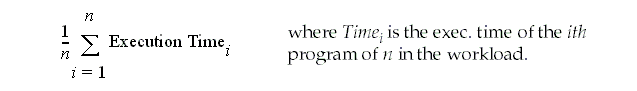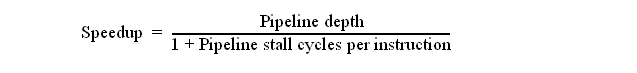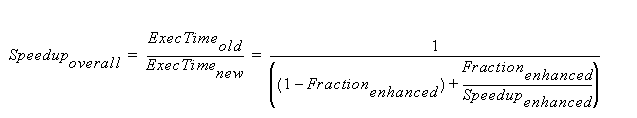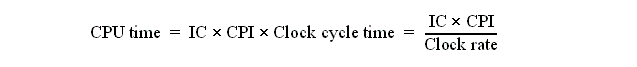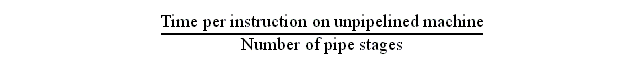-
Technology trends:
-
IC Technology:
-
Density increases 50%/year (~4x in 3 years).
-
DRAM (memory):
-
Density increases about 60%/yr (4x in 3 years).
-
Disk technology:
-
Density improves by 50%/yr (~4x in 3 years).
-
Conclusion:
-
The designer must take these improvements into account and design for a future technology.
-
Cost trends:
-
The learning curve.
-
Volume.
-
Computer X is n times faster than Y is computed as:
-
Measuring Performance:
-
CPU performance: elapsed user CPU time on an unloaded system.
-
Ideal verses the alternative: Benchmarks
-
Arithmetic mean:
-
Harmonic mean, weighted arithmetic mean and weighted harmonic mean.
-
Important design principle:
-
Make the common case fast !
-
CPU Performance Equation:
-
Taxonomy of ISAs:
-
Stack Architecture, Accumulator and General Purpose Register
-
Memory-memory, Register-memory, Load-store
-
Why are GPR ISAs so popular ?
-
Register speed and compiler efficiency.
-
ISA Metrics:
-
Instruction density, Instruction count, Instruction complexity and Instruction length.
-
Memory addressing:
-
What byte is specified by the address ?
-
Alignment
-
Addressing Modes:
-
Register, Immediate, Displacement, Indirect, Indexed, Direct/Absolute, Auto-increment/decrement, Scaling, Memory deferred.
-
Important addressing modes:
-
Register, Immediate, Displacement
-
Immediate field size.
-
Instruction Set operations:
-
Arithmetic/Logical, Load/Stores, Control, System, Floating Point, Decimal, String and Graphics.
-
Control Flow instructions:
-
Conditional branches, Jumps, Procedure Calls, Procedure Returns.
-
Control Flow Addressing modes:
-
PC-relative, Indirect, Absolute
-
Conditional branches:
-
Appropriate field size for offset.
-
Methods of testing the condition
-
Condition codes, condition register and compare and branch
-
Subroutines:
-
Caller saving, callee saving.
-
Instruction encoding:
-
Variable and fixed.
-
Structure of recent optimizing compilers:
-
Front end, High level optimizations, Global optimizations, Code generation.
-
Instruction set properties:
-
Regularity (orthogonality), Provide primitives, not solutions, Simplify trade-off among alternatives, Allow constants to be constants.
-
Non-pipelined DLX:
-
IF, ID, EX, MEM and WB
-
Datapath
-
Pipelined DLX:
-
Datapath
-
Conversion requires separate instruction/data caches, register file modifications, and a means of dealing with branches.
-
Pipelining decrease execution time but increases cycle time due to overhead.
-
Instruction irregularity can not be taken advantage of.
-
Three types:
-
Structural, Data and Control.
-
Simple method to deal with hazards:
-
Stall the pipeline. Previous instruction must proceed to clear hazard.
-
Effect on pipeline speedup (assuming clk cycle time unchanged and unpipelined CPI is equal to depth of pipeline):
-
Structural hazards caused by:
-
Functional units not fully pipelined, shared resources among pipelines.
-
Structural hazards allowed because:
-
They may not occur often enough to justify the cost and they add latency to the unit that is pipelined.
-
Data hazards:
-
Occur when instruction i generates a result read by instruction i+1.
-
Can occur on the register file, on the program counter (actually control hazards) or on a memory location.
-
RAW, WAR and WAW hazards possible.
-
Solutions:
-
Write register in first half of cycle, read in second half.
-
Forwarding.
-
Loads followed by an ALU operation still stall one cycle.
-
Loads followed by a store do NOT need to stall.
-
Compiler scheduling:
-
Compiler reorders instructions to prevent stalls.
-
Increases the number of registers used.
-
Simple if performed within basic blocks.
-
Control hazards:
-
Occur when two instructions accesses to the PC are reordered and the first instruction modifies the PC (RAW).
-
Standard DLX:
-
Three cycle stall.
-
Solutions:
-
Decide branch outcome early in the pipeline.
-
Compute target PC early in the pipeline.
-
DLX datapath modification.
-
Static prediction schemes: (Assume we know target PC and outcome of branch in ID.)
-
Simple: Flush the pipeline.
-
Treat branches as not-taken: flush if branch is taken.
-
Treat branches as taken: doesn't do much good for DLX.
-
Fill branch delay slots.
-
Delayed branch:
-
Filling with an instruction before the branch is always a win.
-
Filling with an instruction from target or from fall through is sometimes a win.
-
Data dependencies prevent the ideal case from being achievable in every situation.
-
When using the alternative, accurate prediction is necessary otherwise, there is no win.
-
Adding a cancelling branch instruction adds flexibility to filling the branch delay slot.
-
Accurate prediction can help with data hazards scheduling as well.
-
In order to reduce branch stall penalties, compilers can:
-
Reorder instructions, Predict all branches taken, Predict forward not taken and backward taken and Use profile information from previous runs.
-
Pipelining difficulties:
-
Exceptions
-
Instruction set complications
-
Exceptions:
-
Types
-
Synchronous vs. asynchronous, User requested vs. coerced, User maskable vs. non-maskable, Within vs. between instructions and Resume vs. terminate
-
Most difficult: resumable exceptions within instructions.
-
Precise vs. imprecise exceptions:
-
All instructions before the faulting instruction complete AND
-
And instructions following the faulting instruction, including the faulting instruction, do not change the state of the machine.
-
Difficulty:
-
Out-of-order instruction completions and out-of-order exception occurrences.
-
One way to maintain precise exceptions.
-
Use a exception vector for each instruction to disable writes.
-
Instruction set complications:
-
Committed instructions are guaranteed to complete.
-
On integer DLX, no updates occur before instruction commit.
-
Precise interrupts are easy.
-
On CISC, this may not be true because of early state changes and memory updates.
-
Defined:
-
Latency and initiation interval.
-
Pipelined FP functional units:
-
Structural hazards for the non-pipelined divide unit and writes to a signal ported register file.
-
Number of register writes that occur in one cycle can be greater than 1.
-
Out-of-order completion: WAW hazards possible and exception handling complicated.
-
RAW stalls more frequent.
-
Solutions to the structural hazard caused by the single write port:
-
Stall the instruction when it tries to enter the MEM.
-
Use a shift register to keep track of register writes and stall in ID.
-
Solutions to the WAW hazard:
-
Stall an instruction that would "pass" another.
-
Cancel the WB phase of the earlier instruction.
-
Handling exceptions:
-
Out-of-order completion causes imprecise exceptions.
-
4 Solutions:
-
Ignore the problem, let them happen.
-
Buffer the results and delay commitment.
-
History file
-
Future file
-
Keep enough information for the trap handler to create a precise sequence for the exception.
-
Allow instruction issue only if it is known that all previous instructions will complete without causing an exception
-
Guideline for instruction set design:
-
Avoid variable instruction lengths and running times whenever possible.
-
Avoid sophisticated addressing modes.
-
Don't allow self-modifying code.
-
Avoid implicitly setting CCs in instructions.
-
Focus on reducing RAW and control stalls.
-
Increases importance in dealing with WAR, WAW and structural stalls.
-
Techniques:
-
Loop unrolling, Basic pipeline scheduling, Scoreboarding, Register renaming, Dynamic branch prediction, Issuing multiple instructions per cycle, Compiler dependence analysis, Software pipelining and trace scheduling, Speculation, Dynamic memory disambiguation
-
Pipeline scheduling:
-
Compiler seeks to separate a dependent instruction from the source instruction by a distance (in clk cycles) equal to the pipeline latency of the source.
-
Instructions are reordered, offsets adjusted.
-
Pipeline scheduling and loop unrolling improves scheduling by:
-
It eliminates branches.
-
It allows instructions from different iterations to be scheduled together, it exposes parallelism.
-
Dependences:
-
Properties of programs.
-
Indicate the potential for a hazard.
-
Actual hazard and the length of any stall is a property of the pipeline.
-
Three types:
-
Data, name and control.
-
Data dependencies can be overcome:
-
Maintaining the dependence but avoiding a hazard (hardware and software).
-
Eliminating the dependence by transforming the code (software only).
-
Fold computation into an offset.
-
Name Dependences:
-
Occur when two instructions use the same register or memory location but there is NO flow of data between instructions that use that name.
-
Antidependence, Output dependence.
-
Can be executed out of order or in parallel.
-
Register renaming can either be done by the compiler or the CPU.
-
Control Dependences
-
A control dependency determines the ordering of the instructions with respect to branch instructions.
-
Preserving control dependence is not important -- program correctness is.
-
Preserving exception behavior, Preserving data flow
-
Control stalls can be avoided by:
-
Scheduling instructions in delay slots.
-
Loop unrolling.
-
Conditional execution.
-
Speculation (by both compiler and CPU).
-
The CPU rearranges the instructions (while preserving dependences) to reduce stalls.
-
Advantages over static (compiler) schemes:
-
Handles dependencies that are UNknown at compile time (i.e., a memory reference.)
-
Allows code compiled with one pipeline in mind to run efficiently on a different pipeline.
-
Out-of-order execution: Split ID into:
-
Issue: Decode and check for structural.
-
Read operands: Wait until no data hazards and read operands.
-
Scoreboarding:
-
Goal: to maintain an execution rate of one instruction per cycle.
-
Instructions can bypass each other in Read Operands. WAW hazards possible.
-
Hazard detection and resolution are centralized.
-
Scoreboarding:
-
Issue (IS)
-
The functional unit is available and
-
No other active instruction has the same destination register.
-
This avoids WAW hazards and structural hazards.
-
Read Operands (RD)
-
Resolves RAW hazards dynamically
-
Write result (WB)
-
The scoreboard checks for WAR hazards and stalls the completing instruction if necessary.
-
Components of the system:
-
Instruction status, Functional unit status, Register result status
-
Distinguishing between RAW and WAR:
-
Check the value of Rj or Rk for Yes
-
Scoreboarding: Limitations:
-
ILP, Size of the "issued" queue, Number, types, and speed of the functional units, The presence of antidependences and output dependences.
-
Tomasulo's approach:
-
A technique to allow execution to proceed in the presence of hazards.
-
Renames registers dynamically:
-
Eliminating WAW and WAR hazards.
-
Differences between scoreboarding and Tomasulo's approach:
-
Register renaming, Distributed control and the Common Data Bus.
-
Operation steps:
-
Issue: Check for structural hazards. Rename source operands if necessary.
-
Execute: Handle RAW hazards
-
Write result: Update reservation stations and register file.
-
Tomasulo's advantages and characteristics:
-
The distribution of the hazard detection logic.
-
The elimination of WAW and WAR hazards.
-
Dynamic loop unrolling.
-
Memory disambiguation.
-
Dynamic Branch Prediction
-
Prediction Accuracy and Latency
-
Branch-Prediction Buffer
-
Helps when branch decision takes longer to compute than target PC.
-
Keep a buffer (cache) indexed by the lower portion of the address of the branch instruction.
-
Incorrect branching may result from misprediction or instruction mismatch.
-
2-bit scheme fixes 2 miss problem in nested loops.
-
n-bit prediction with a saturating counter not much better than a 2-bit predictor.
-
Correlating Branch predictors:
-
Considers the behavior of "surrounding" branches.
-
2-level correlated predictor:
-
Each branch keeps track of the behavior of the previous branch, and uses that to predict the behavior of the current branch.
-
(m,n) predictors:
-
Use the behavior of the last m branches to choose from one of 2m branch predictors, each of which is an n-bit predictor.
-
Branch-Target Buffers (BTB)
-
A method to reduce branch stalls to 0.
-
Value" in the cache is the address of the next instruction.
-
Compare the entire address, a cache.
-
Prediction can be added to the Branch-Target Buffer, preferably in a separate buffer.
-
Misprediction penalties can be higher since updating the cache interferes with the comparison of the PC on each instruction fetch.
-
Branch folding:
-
Instead of storing just the branch address, the BTB can store the actual instruction as well.
-
For unconditional branches or CCs, the branch "disappears".
-
Multiple Issue CPUs
-
Superscalar: Utilize both static and dynamic scheduling strategies.
-
VLIW: Statically scheduled only.
-
Superscalar DLX
-
Interactions between integer and FP
-
Contention for the FP register ports and RAW hazards between integer FP loads/stores and FP ALU instructions.
-
Hazards impose a penalty measured in cycles, not instructions
-
VLIW
-
Each VLIW "instruction" is composed of multiple independent instructions.
-
Compiler unrolls loops and schedules code across basic blocks.
-
Limits in multiple-issue processors:
-
Limits on available ILP in programs
-
Hardware complexity: memory bandwidth and design complexity.
-
Limitations specific to superscalar or VLIW
-
Superscalar
-
Instruction issue logic is the primary challenge with superscalar
-
VLIW
-
Increase in code size from open slots.
-
Effect of stalls on a lock-step operation.
-
Binary compatibility.